


Tech
High Performance NVMe Storage Is Perfect for MicroService Architecture
There are many Kubernetes storage providers in the market, and to find the right one, you need to understand what you should go for. Kubernetes is the preeminent container orchestration platform and is useful in the development and deployment of applications with the microservice architecture.
The right storage solution for a microservice architecture implemented through containers should be scalable enough for stateful applications. It should also provide high speed and performance in addition to reliability.
Traditional storage solutions are not the answer. They come with a bevy of performance and scalability problems as we will see below. Instead, a solution that enables infrastructure architects to leverage intelligent software and state-of-the-art flash storage is the way to go.
A Micro-Service Architecture Makes Businesses More Competitive
Traditional storage architecture wasn’t designed for microservices yet more teams are favoring a microservice approach to deployment.
Breaking down a monolithic application into microservices has many benefits. One of the major ones is the ability to upgrade a microservice without affecting other parts of the application. This makes upgrades faster and more cost-efficient.
Another key benefit of a microservices architecture is that it boosts innovation. As opposed to centralized release coordination, microservices enable the engineering teams responsible for different services to make independent decisions and focus on continuous delivery and improvement.
There are many other benefits to microservices, including improved scalability, more resilient applications, faster time-to-market, and improved business agility.
Using Microservices on Traditional Storage Solutions is Limiting
When microservices first came into the picture, they were stateless. They didn’t need to generate and store new data to handle client requests. However, with time, data from microservices was needed for analytics, including for machine learning and artificial intelligence.
With microservices generating data, storage problems arose. Organizations could have hundreds or thousands of microservices generating data. Yet traditional block storage was not designed to be quickly mapped to and then detached from data sources. This became a problem from the viewpoint of performance and reliability.
There were other problems. With containers that could have a lifetime of seconds, it was difficult for monitoring tools to generate reliable audit logs. It thus became a problem to prove that the storage, encryption, and use of data was in compliance with regulations.
There were also problems with backup and data recovery as most archiving tools were suited for virtual machines, not containers.
High-Performance NVMe Provides Scalable and Persistent Storage for Containers
Traditional storage, when used with containers, resulted in a range of constraints for performance, flexibility, and scalability.
Container storage needs to be fast, with speeds similar to those of local flash. But it also needs the flexibility and data protection provided by centralized storage. To satisfy both sets of requirements, storage architects have been relying on proprietary, hardware-based storage solutions.
However, there is a better way.
Pooled, redundant, high performance NVMe storage can be used to provide persistent, low-latency container storage for microservice architectures. There are already a number of Kubernetes storage providers offering such solutions.
High performance NVMe storage for Kubernetes comes with multiple advantages. It enables the speed and performance of local flash storage. In addition, it provides a storage solution that is not only scalable enough for stateful applications but also offers protection against drive or host failure.
The Advantages of High-Performance Storage for Containers
Local Speeds and Latencies
NVMe storage features a distributed block layer that allows the utilization of pooled storage across the devices in a network. This allows local speeds and latencies at the network level. Containers can enjoy significantly improved throughput, IOPS, and latency.
Central Administration
This software-defined-networking solution creates arbitrary, dynamic, virtual volumes that can be used by any host running the software. These volumes can be mirrored or stripped. At the same time, they are monitored and managed centrally.
Freedom in Architectural Design
Since this solution relies on a virtual, distributed, non-volatile array, it can be used both with disaggregated and converged design, giving businesses full freedom in architectural design.
Improved Scale and Performance
Businesses can leverage the full performance of NVMe storage at the network level, and at any scale. In addition to persistent storage that scales, businesses also benefit from predictable application performance.
Performance and capacity can also be scaled linearly.
Efficiency
Since this is a software-defined solution, the hardware used can be from any vendor. It also allows the maximum utilization of the NVMe flash devices available to a business. In addition, it’s easier to balance CPU and storage resources and the ease of management and monitoring reduces the total cost of ownership.
Flexibility
Though the containers in a pod have access to the persistent storage availed to that pod, they have the freedom to restart the pod on another host.
The architecture can also be converged, disaggregated, or mixed and different storage media types can be used together to optimize for performance, scale, and cost.

Enterprise AI copilots and automation assistants now sit inside email, CRM systems, ITSM platforms, and office productivity suites, each with its own defaults and its own blind spots. The six practices below apply across that whole category, regardless of which specific copilot or automation platform an organization has deployed.
1. Scope permissions before the copilot ever touches production data
Default permission scopes on most enterprise copilots are broader than the actual task requires. Reviewing and narrowing Copilot Studio security controls before rollout, rather than after an incident, is consistently the highest-leverage step available.
2. Extend the same scrutiny to CRM-embedded AI features
CRM platforms have added AI agent capabilities directly into workflows that already touch customer and financial data. Reviewing Salesforce AI governance settings with the same rigor applied to a standalone AI deployment closes a gap that is easy to overlook simply because the AI feature lives inside a familiar, already-trusted system.
3. Apply consistent audit logging across every AI-enabled platform
Audit logging that only covers some AI-enabled platforms creates blind spots at exactly the boundary attackers look for. Extending consistent logging to ServiceNow AI governance workflows, alongside better-monitored platforms, keeps the audit trail continuous rather than fragmented by system.
4. Don’t treat RPA-driven agents as a separate, lower-priority category
Automation platforms built for citizen developers often run with elevated service-account permissions by default. Applying the same review standard to UiPath security for citizen developers that gets applied to newer generative AI deployments avoids a gap that opens simply because the technology predates the current AI security conversation.
5. Validate inputs the copilot processes, not just the copilot’s own configuration
A well-configured copilot can still be manipulated through the documents, emails, or tickets it is asked to summarize or act on. Input validation needs to account for instructions embedded inside that content, not just the copilot’s own settings.
This distinction matters because most security reviews stop at configuration. They confirm the copilot has the right permission scope and the right access controls, then treat the review as complete. That leaves the content the copilot processes every day almost entirely unexamined, even though it is the most common path an attacker actually has into the system.
6. Monitor behavior continuously rather than relying on a launch-time review
A copilot’s risk profile is not fixed at deployment. Permissions get modified, integrations get added, and underlying models get updated. Continuous monitoring is what catches drift between how the copilot was reviewed and how it is actually being used months later.
In practice, this is the control most organizations plan to add eventually and never quite prioritize, largely because launch-time review produces a clear pass or fail while ongoing monitoring requires sustained attention with no single moment of completion. That is exactly why it tends to be the gap attackers rely on most.
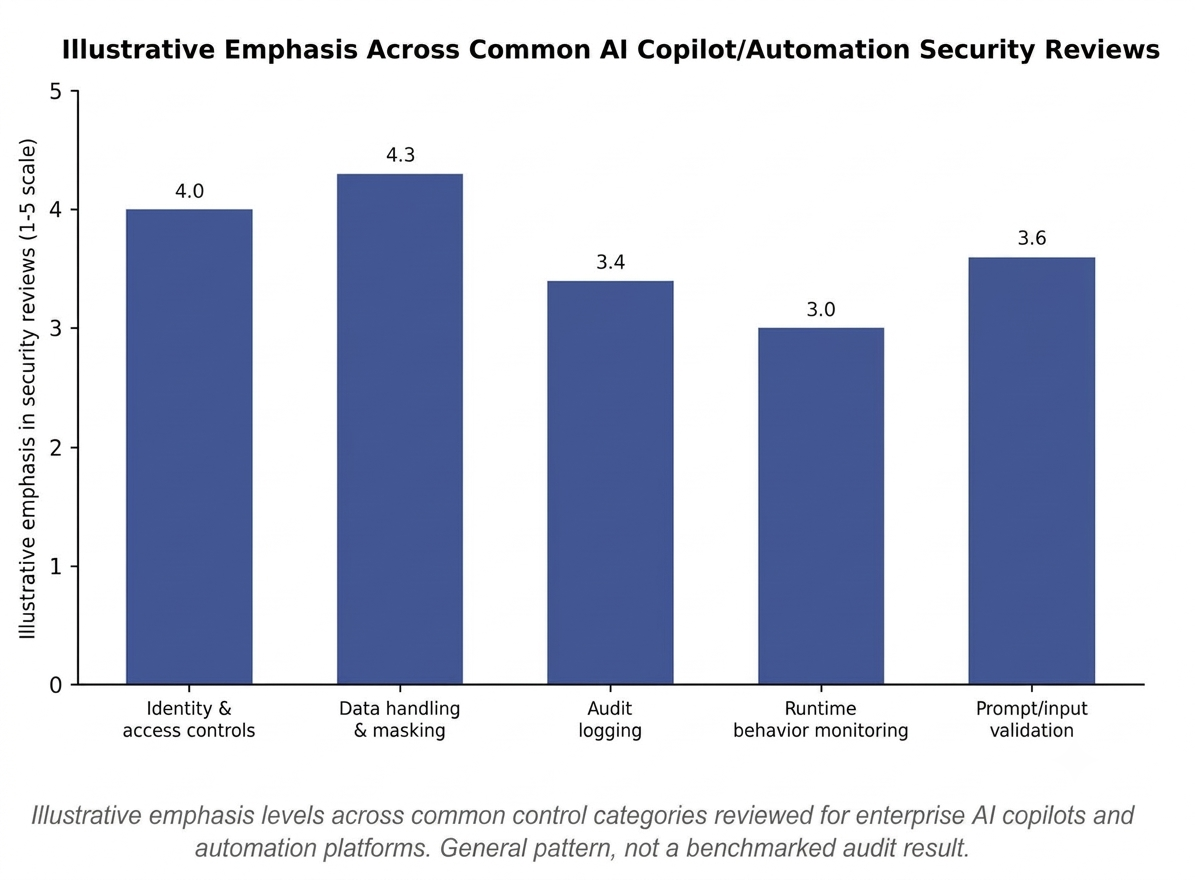
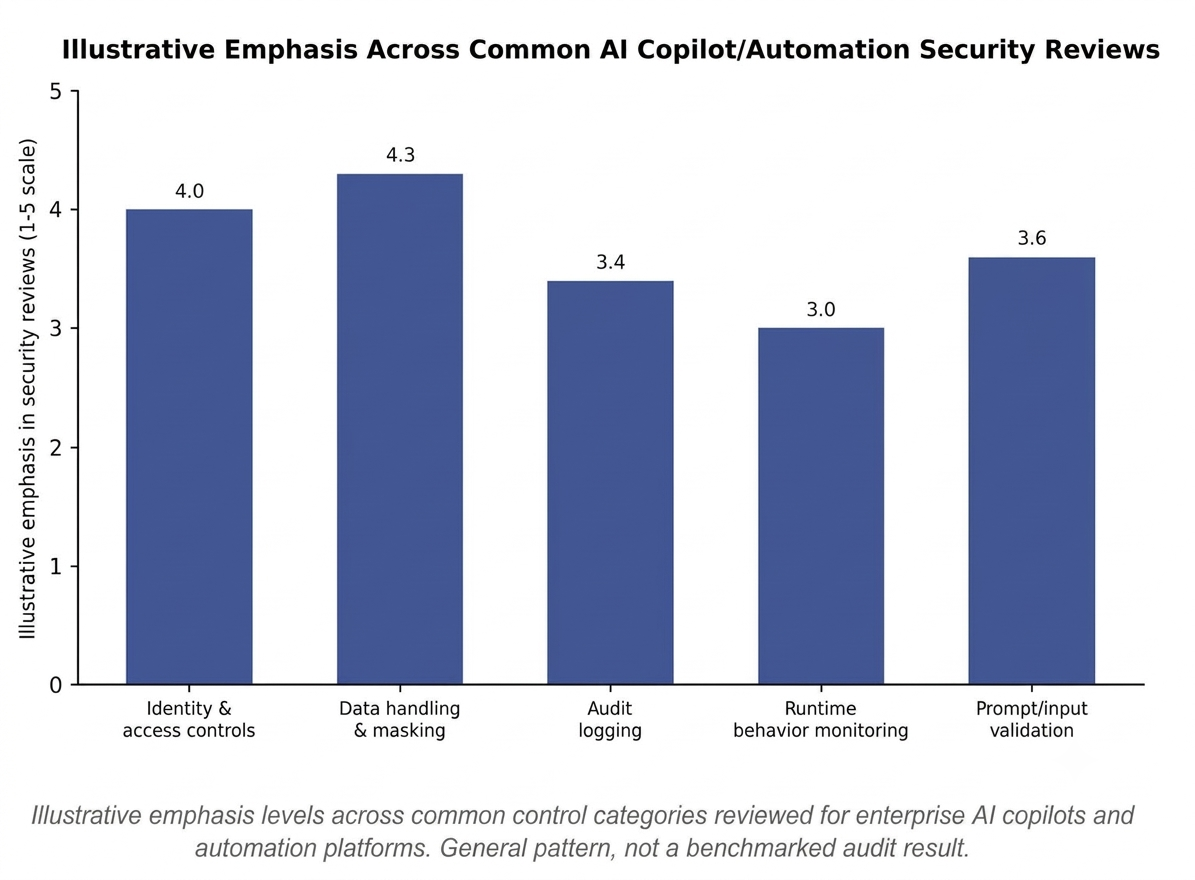
Illustrative emphasis levels across common control categories reviewed for enterprise AI copilots and automation platforms. General pattern, not a benchmarked audit result.
How six core security controls typically apply across different categories of enterprise AI copilots and automation tools. General guidance, not a vendor-specific audit.
| Control Category | AI Copilots in Productivity Suites | CRM-Embedded AI Agents | ITSM AI Assistants | RPA / Automation Platforms |
| Permission scoping | High priority | High priority | Medium priority | High priority |
| Audit logging depth | Often inconsistent | Improving | Often inconsistent | Frequently overlooked |
| Input validation for embedded content | Critical | Critical | Medium priority | Medium priority |
| Runtime behavior monitoring | Emerging practice | Emerging practice | Emerging practice | Frequently overlooked |
Where This Leaves Security Teams
None of these six practices is unique to a single vendor or platform category. What varies is how consistently each one gets applied once an organization has more than one type of AI copilot or automation tool in production. Treating all of them, generative copilots and older RPA platforms alike, against the same six-practice baseline tends to close the gaps that show up when one category gets more security attention than another simply because it is newer or more visible.
Frequently Asked Questions
Are RPA platforms less risky than generative AI copilots?
Not inherently. RPA and automation platforms often run with elevated service-account permissions and can be overlooked in security reviews simply because they predate the current wave of generative AI tools, which can leave real gaps if they are treated as lower priority.
What is the most overlooked security control for enterprise AI copilots?
Runtime behavior monitoring is commonly the most overlooked, since most security reviews still focus on configuration at launch rather than ongoing behavior after the copilot has been in use for a while.
Do CRM-embedded AI agents need a separate security review from standalone AI tools?
Yes, in practice they often need dedicated attention because they are embedded inside a system that is already trusted and already touches customer and financial data, which can make new AI features an afterthought in the review process.
Archives sitting on shelves of negatives, glass plates, and slides face a quiet but real deadline: analog film degrades, and every year that passes without digitization is a year closer to information loss that cannot be undone. The good news is that film digitization has matured well beyond the flatbed scanners most people picture. Here is an honest look at the main approaches available to an institution weighing this decision today, and where each one actually fits.
Flatbed scanning: the familiar starting point
Flatbed scanners are the most widely available option and the lowest barrier to entry, which is exactly why so many small archives start here. The tradeoff is speed and, at scale, consistency. Each frame is captured through a slow, mechanical pass, and results can vary depending on how consistently an operator loads and positions material. For a modest personal collection or a small batch of prints, this is often perfectly adequate. For a collection running into the thousands or tens of thousands of frames, the math stops working: the time cost compounds quickly.
Drum and virtual drum scanners: higher quality, higher overhead
Drum scanners have long been considered a high-quality option, particularly for capturing fine tonal detail in transparencies, and virtual drum scanners attempt to replicate that quality without the physical drum. Both, however, remain fundamentally slow, point-by-point or line-by-line capture methods. They also tend to require more specialized operator skill and ongoing maintenance than either flatbed or camera-based systems, which raises the effective cost per image once staff time is factored in alongside the equipment itself.
Camera-based digitization: built for volume without giving up quality
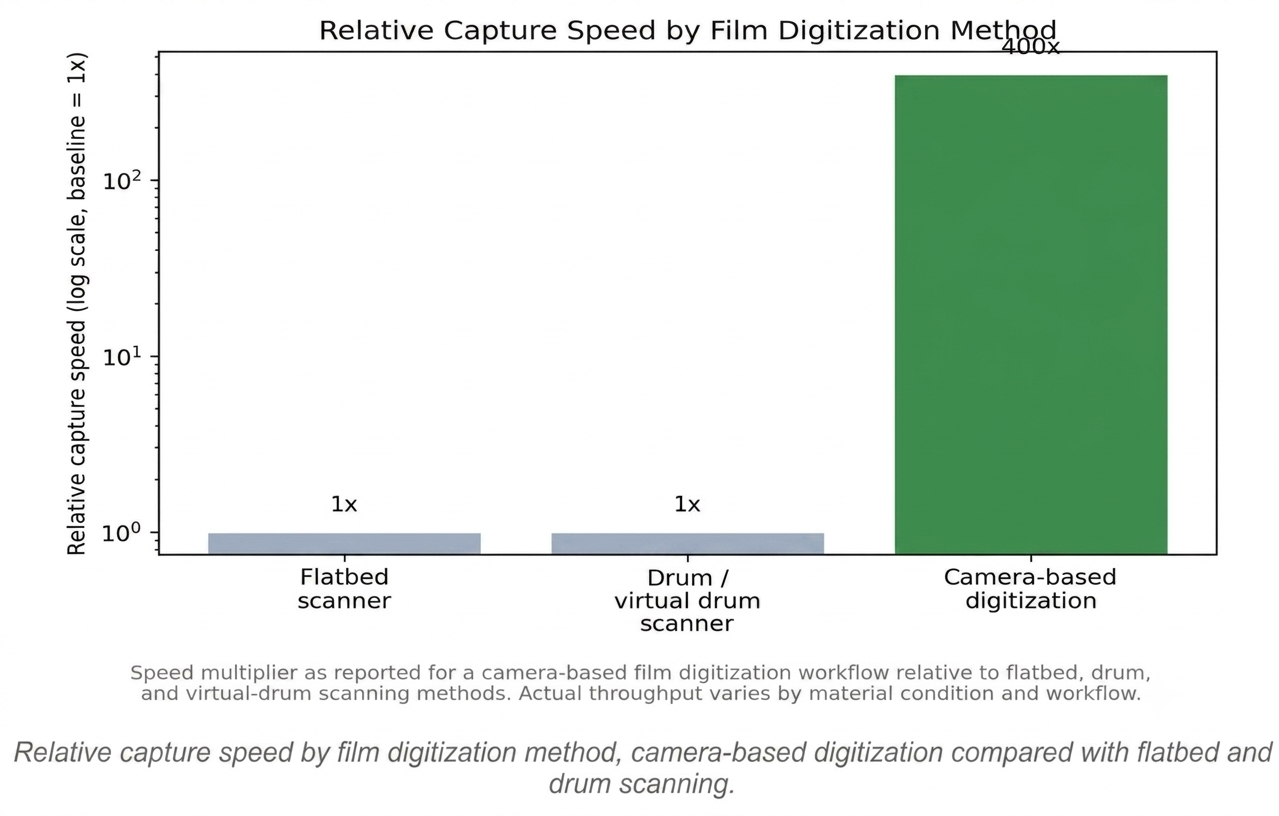
The more recent shift in serious archival digitization has been toward camera-based systems: a high-resolution digital sensor paired with a dedicated film capture stage, specialized film and glass-plate carriers, and copy-stand hardware, all built specifically to hold negatives, transparencies, and plates flat and properly illuminated during capture. Because the entire frame is captured in a single, near-instant exposure rather than built up progressively, throughput increases dramatically. One documented high-volume digitization workflow using an iXG camera system reports capture rates fast enough to process a full frame in a fraction of a second, cited as roughly 400 times faster than flatbed, drum, or virtual-drum scanning for comparable material.
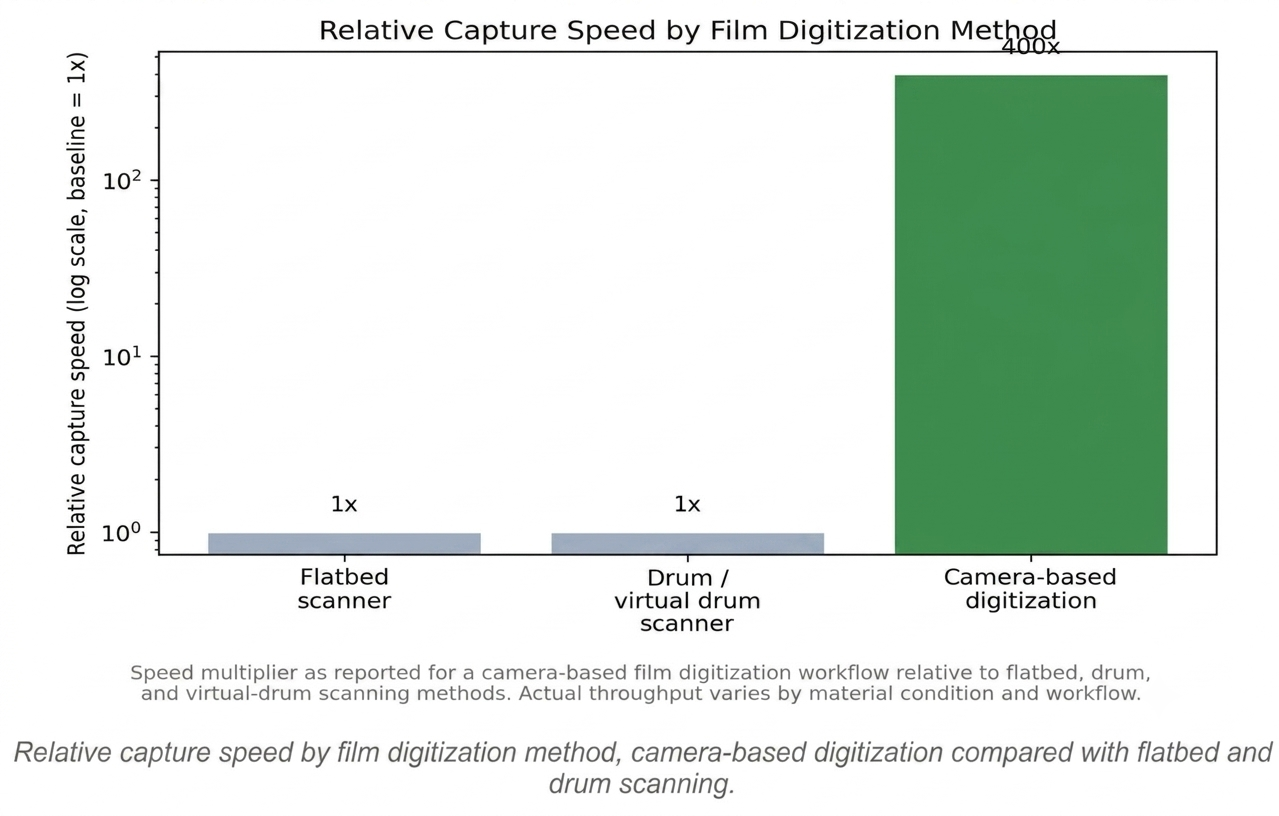
Relative capture speed by film digitization method, camera-based digitization compared with flatbed and drum scanning.
Does faster mean lower quality?
This is the question every archivist asks first, reasonably so, and the answer depends entirely on whether a program follows recognized technical benchmarks. Standards such as those maintained by the Federal Agencies Digital Guidelines Initiative, widely referred to as FADGI, and the Dutch Metamorfoze guidelines exist precisely to give institutions an objective way to verify image quality regardless of which capture method produced it. A camera-based system built around flat-field optics, precise focus tools, and accurate color profiling can meet the same three- and four-star quality benchmarks that a slower method targets, while doing it in a fraction of the time. Speed and quality are not automatically in tension; the real variable is whether the equipment and workflow were designed to hold quality steady at higher throughput.
What should actually drive the decision?
- Collection size: small, occasional digitization jobs rarely justify the cost of a dedicated camera-based setup, while collections in the thousands of items usually cannot avoid it on a cost-per-image basis.
- Material variety: mixed collections containing negatives, glass plates, slides, and bound volumes benefit from a modular setup that can switch between capture stages rather than requiring separate dedicated machines for each format.
- Compliance requirements: institutions submitting digitized material to federal, academic, or museum standards need to confirm their chosen workflow can actually document and pass the relevant FADGI or Metamorfoze star rating, not just claim high resolution.
- Staff capacity: drum and virtual drum scanning generally demand more specialized, ongoing operator expertise than a well-designed camera-based workflow, which matters for institutions without a dedicated imaging technician on staff.
There is no universally correct answer here, only a correct answer for a given collection’s size, format mix, and compliance needs. What has changed in recent years is that the fastest option is no longer automatically the lowest-quality one, which means the old tradeoff between speed and archival integrity is far less absolute than it used to be.
Frequently Asked Questions
Is camera-based film digitization actually faster than scanning?
Yes, documented workflows report camera-based capture running at roughly 400 times the speed of flatbed, drum, or virtual-drum scanning for comparable material, since the full frame is captured in a single exposure.
Does faster film digitization mean lower image quality?
Not inherently. Quality depends on whether the equipment and workflow are built to meet recognized benchmarks such as FADGI or Metamorfoze star ratings, regardless of the capture method used.
What type of archive benefits most from camera-based digitization?
Larger or mixed-format collections, such as those combining negatives, glass plates, and slides, generally see the greatest benefit, since a modular camera-based setup can switch between formats without separate dedicated machines.
Two years ago, a guardrail conversation was mostly about content filtering: stop the chatbot from saying something toxic. The model produced text, the text was safe or it was not, and a classifier could usually tell. In 2026 the problem changed shape, because the model is no longer just producing text. It is calling APIs, querying databases, writing files, sending emails, and triggering workflows. A guardrail failure two years ago meant a bad response. A guardrail failure today can mean a bad action: data deleted, funds transferred, privileged information forwarded to the wrong recipient. Here are seven signs an enterprise’s guardrail approach has not caught up to that shift.
- Guardrails only inspect the chat interface
If the only place content is being checked is the conversational turn between user and model, agentic workflows are moving around that checkpoint entirely. Tool calls, intermediate outputs passed between chained steps, and data pulled from connected systems all need coverage, not just the visible chat window.
- There is no human checkpoint on irreversible actions
Database deletions, external data transfers, financial transactions, and bulk record modifications are operations where a mistaken or manipulated instruction can cause damage that is difficult or impossible to reverse. Enterprises that have not annotated their AI tools by risk level, and built approval flows for anything tagged destructive, are relying entirely on the model getting it right every time.
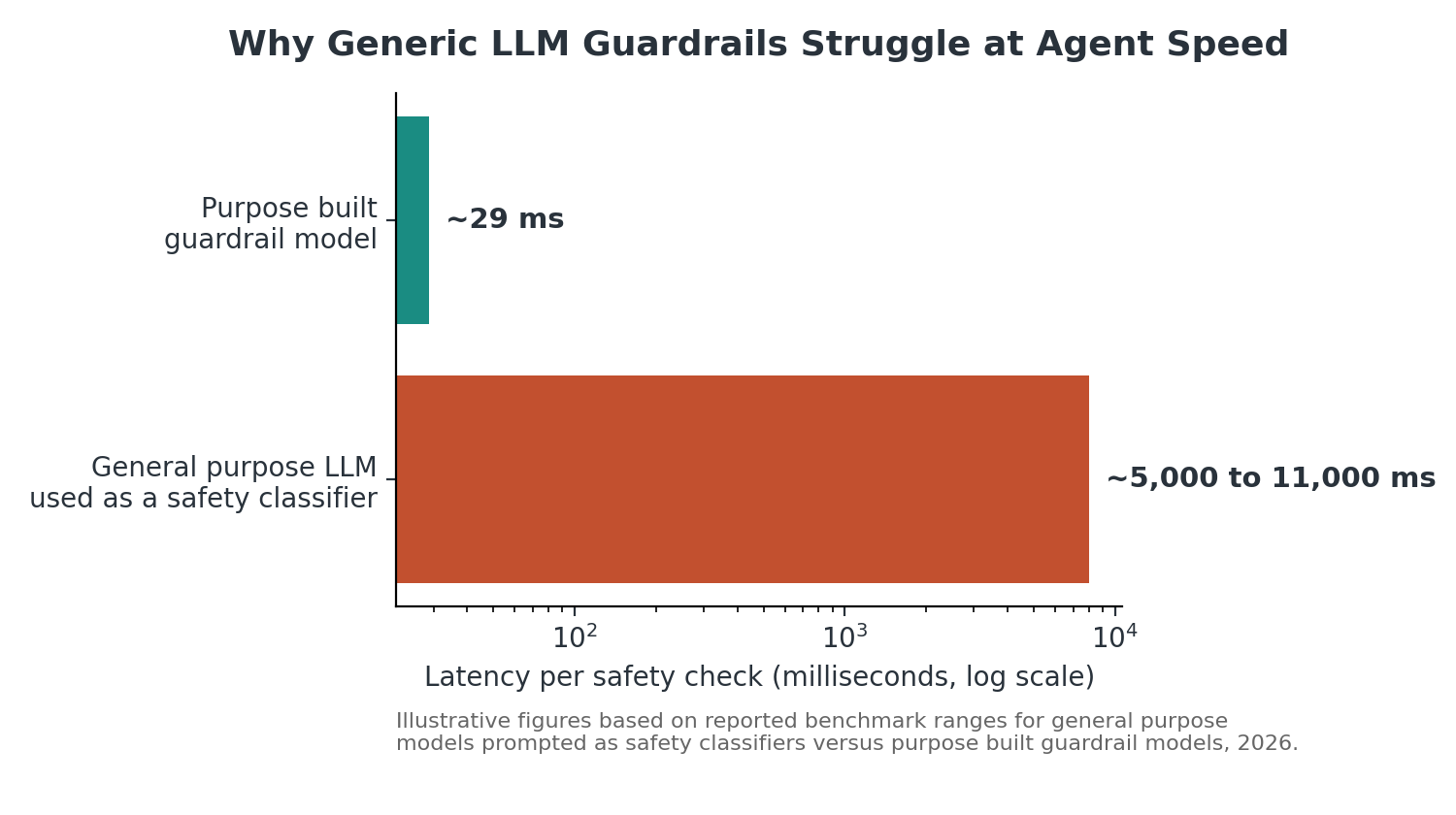
- The guardrail is a prompted general purpose model
Prompting a general purpose model to act as its own safety classifier is the fastest way to prototype a guardrail, and it is also the slowest one to run in production. The chart below shows why that tradeoff matters once guardrails sit inside an agent’s decision loop rather than at the end of a conversation.
Illustrative figures based on reported benchmark ranges for general purpose models prompted as classifiers versus purpose built guardrail models, 2026.
- Policies are generic instead of specific to the workflow
Out of the box guardrails ship with a fixed taxonomy covering hate speech, violence, sexual content, and basic PII. That is fine for a generic chatbot. It is not fine for a workflow that needs to enforce specific regulatory language, recognize an organization’s own confidential project names, or apply industry-specific rules no generic model has ever seen. Generic guardrails catch generic problems and miss the ones that actually matter to a given business.
- There is no governance layer over employee AI usage
Guardrails on a single deployed application do nothing for the AI tools employees adopt on their own. Consistent governance over employee AI tool usage across sanctioned and unsanctioned tools alike is what turns a guardrail policy from something that applies to one system into something that actually reflects how AI is used across the organization.
- Nobody has adversarially tested the guardrail itself
A guardrail that has only been validated against the cases it was designed to catch will fail the first time it meets an adversarial input it was not trained on. Open source community-standard guard models, for example, see measurable accuracy drops under adversarial pressure and on long context traces compared to their baseline performance. Red teaming the guardrail, not just the underlying model, is what closes that gap before an attacker finds it.
- Governance is only 25 percent implemented, if that
According to a 2025 industry survey, only about 25 percent of companies report a fully implemented AI governance program, even as 88 percent of organizations say they use AI in at least one business function. That gap between usage and governance is exactly where the enterprise AI security risks CISOs are already tracking tend to surface first, since guardrails without an underlying governance program are enforcing rules nobody has actually agreed on organization-wide.
What closing these gaps actually requires
The pattern across all seven signs is the same: guardrails designed for a single conversational turn do not generalize to a system that acts. Closing the gap means covering tool calls and not just chat, gating irreversible actions behind human review, using purpose-built models fast enough to run inline, tailoring policy to the specific workflow, extending governance to tools employees adopted informally, adversarially testing the guardrail itself, and treating all of it as a program rather than a one-time deployment. A recent look at how enterprises are approaching the related discipline of preventing AI data leakage is worth reading alongside guardrail planning, since the two controls typically need to work together
Frequently Asked Questions
Are guardrails the same thing as AI governance?
No. Guardrails are the runtime controls that catch or block specific behaviors. Governance is the broader program, ownership, policy, and accountability structure that decides what those controls should actually enforce.
Why do agentic systems need different guardrails than chatbots?
Chatbots produce text a human reads before acting on it. Agents can take the action directly, so a guardrail failure has a much larger and sometimes irreversible blast radius, which changes both what needs to be checked and how fast the check needs to run.
What is the fastest way to test whether current guardrails are sufficient?
Red team them the same way the underlying model would be tested, using adversarial examples specific to the organization’s actual policies and workflows rather than relying only on the vendor’s published benchmark results.
The 6 Best Practices for Securing Enterprise AI Copilots

The Best Ways to Digitize Analog Film Without Losing What Made It Analog
A Practical Framework for B2B Digital Marketing in the Technology Sector

-

 Business Solutions2 years ago
Business Solutions2 years agoLive Video Broadcasting with Bonded Transmission Technology
-

 Business Solutions1 year ago
Business Solutions1 year agoThe Future of Healthcare SMS and RCS Messaging
-

 Business Solutions2 years ago
Business Solutions2 years ago2-Way Texting Solutions from Company Message Services
-

 Business Solutions2 years ago
Business Solutions2 years agoCommunication with Analog to Fiber Converters & RF Link Budgets
-

 DSRC Communication1 year ago
DSRC Communication1 year agoThe Crossroads of Connectivity: DSRC vs. C-V2X Technologies in Automotive Communication
-
Electronics3 years ago
AI Modules and Smart Home Chips: Future of Home Automation
-

 Business Solutions2 years ago
Business Solutions2 years agoWholesale SMS Platforms with OTP Services
-

 Business Solutions1 year ago
Business Solutions1 year agoChoosing the Right B2B Digital Marketing Agency: A Guide