


Tech
The Critical Technical SEO Audit Checklist for Enterprise SaaS Environments
Enterprise Software-as-a-Service (SaaS) web platforms manage highly complex digital environments. Because these sites use dynamic code frameworks, localized subdomains, gated resource hubs, and continuous product updates, they are highly prone to hidden technical errors. Issues like broken internal redirect loops, unmapped crawl paths, and slow JavaScript rendering can quickly harm search rankings. When search engine bots encounter these technical barriers, they reduce their crawl frequency, which leaves new product landing pages unindexed for weeks. For a fast-growing SaaS business, these technical blind spots can hurt customer acquisition speeds and lower long-term digital ROI.
To eliminate these infrastructure risks, successful tech companies treat technical optimization as a core engineering task. Running systematic, highly rigorous data audits allows operations teams to locate and resolve indexation bottlenecks before they impact organic traffic. This review details the technical benchmarks needed to pass an enterprise-grade audit, explains why clean site architecture affects crawl efficiency, and outlines the mechanical advantages that separate automated, real-time indexation tracking from basic manual site reviews.
Maximizing Crawl Budgets via Structural Health
Search engine crawlers allocate a limited amount of processing time—known as a crawl budget—to every website. On large SaaS platforms containing thousands of dynamic pages, a significant portion of this budget is often wasted on broken links, duplicate parameters, or unnecessary redirect loops. This fragmentation prevents core marketing pages and high-value conversion funnels from being indexed efficiently.
Passing a professional technical evaluation requires securing a clean, shallow crawl path that allows search bots to reach any page on the site within three clicks of the homepage. Incorporating a rigorous, data-driven framework like the one used in SEO Audits ensures that server errors and duplicate content paths are eliminated, maximizing the value of your search engine crawl budget.
Remediation Timeline: Compressing Search Bot Latency
When a site’s backend architecture is systematically cleaned of code bloat and unmapped loop strings, search engine spiders can re-index system modifications at a dramatically accelerated pace:
-
Pre-Audit Baseline: 18 Days indexation latency due to broken redirect lines and unmapped paths.
-
Wave 1 (Technical Corrections): 5 Days indexation latency achieved immediately after cleaning redirect chains and fixing server response blocks.
-
Wave 2 (GEO Alignment Framework): Less than 24 Hours re-indexing turnaround realized by generating static, clean schema maps.
Content Visibility Across Generative Engines
Beyond traditional text indexing timelines, backend code optimization directly establishes how effectively autonomous scrapers map context to serve conversational search platforms.
The visibility metric diagram below highlights the probability breakthroughs achieved when transitioning from legacy text formats into optimized data delivery architectures:
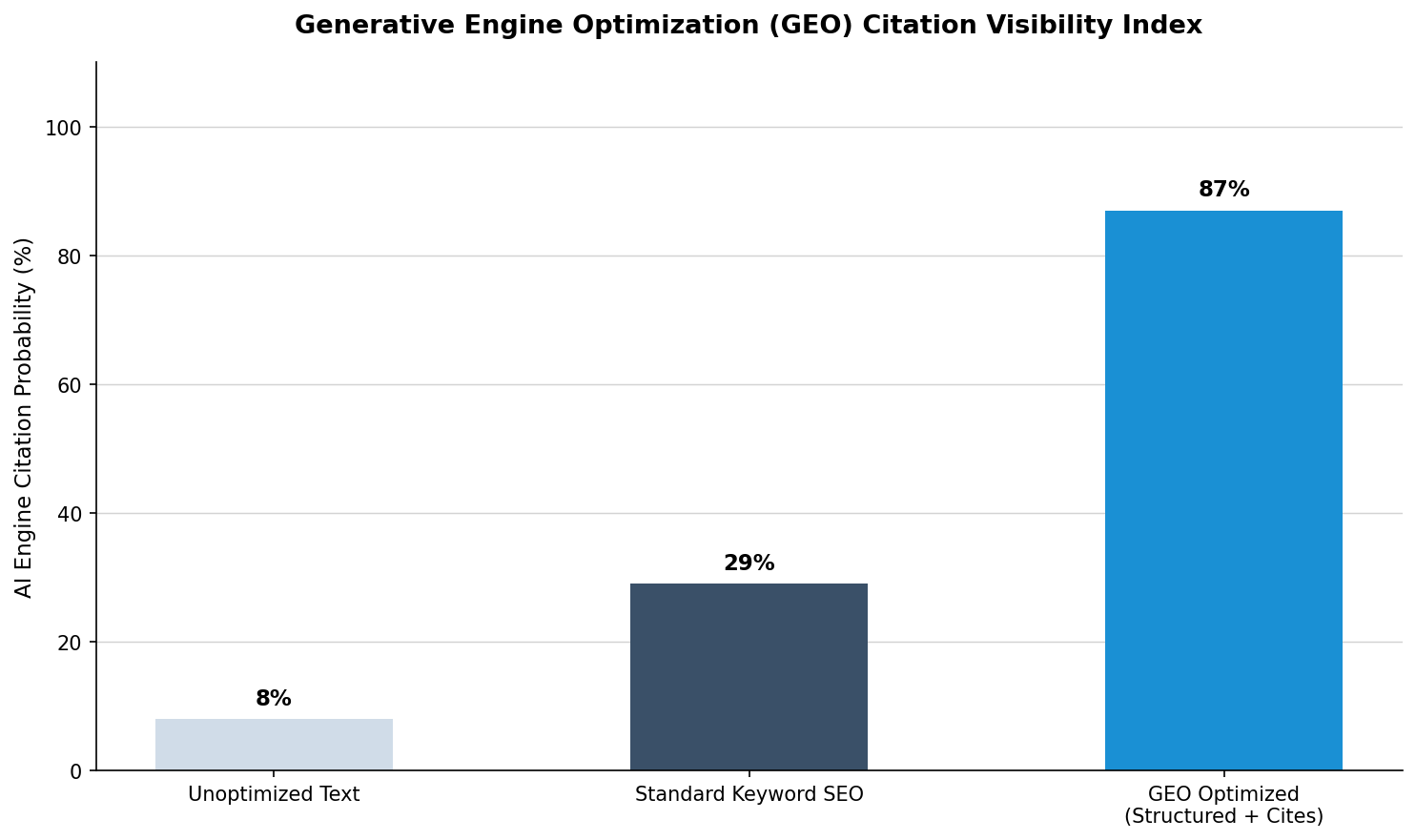
Optimizing Dynamic Frameworks for Modern Scrapers
Many modern SaaS platforms use JavaScript-heavy client-side rendering (such as React, Angular, or Vue) to build fast, interactive user interfaces. While this creates a great experience for human visitors, it often presents major challenges for search engine scrapers, which may fail to execute the underlying scripts correctly during their initial pass. This leaves behind a blank or partially rendered page that cannot be indexed accurately.
To fix this rendering gap, engineering groups must implement Server-Side Rendering (SSR) or dynamic pre-rendering configurations across their entire web presence. Combining these advanced server changes with optimized schema markup provides search engines with pre-built, instantly readable content. Following an expert, step-by-step framework for Technical SEO for SaaS Companies ensures that your digital infrastructure remains highly visible, turning technical perfection into a reliable engine for long-term organic growth.
Conclusion
Technical integrity forms the baseline of any successful enterprise digital expansion strategy. If a website possesses broken crawl links or unreadable script payloads, even the highest-quality content will fail to rank or find its way into AI responses. By approaching technical health as an engineering priority and executing systematic data updates, SaaS enterprises can build highly scalable, fast-loading platforms that lock down maximum search traffic natively.

The long-term commercialization of complex software frameworks cannot rely on financial support alone. Emerging technology segments—ranging from cloud-native software layers to hardware-integrated medical instruments—face distinct operational constraints that defy uniform generalist strategies. Startups navigating the long validation timelines of clinical certifications or the severe code-hardening requirements of critical infrastructure defenses must align with specialized capital networks. If an early-growth company partners with generalist finance groups that lack deep industry insights, it faces significant risks of structural misalignment, missed validation deadlines, and premature failure within competitive international supply chains.
To minimize these market integration risks, institutional innovation pipelines are deploying a specialized, target-grouped enterprise software venture capital framework. Rather than spreading generalist funds thinly across unconnected industries, specialized models isolate individual investments within specific, highly technical verticals. This comprehensive analysis evaluates the structural scaling mechanics across high-barrier domains, outlines why cross-industry groupings require distinct advisory protocols, and details how targeted vertical incubation pathways insulate tech firms from broader macroeconomic market shifts.
Vertical Customization Across Specialized SaaS Platforms
Modern business systems are moving away from horizontal, general-purpose applications in favor of highly specialized, vertical-specific software solutions. Startups developing deep algorithmic tools for complex workflows, such as financial audit automation or high-performance data pipeline monitoring, require specialized infrastructure support from day one. These companies face unique go-to-market challenges, including complex technical evaluations and specialized data localization regulations.
Partnering with a specialized software venture capital firm portfolio structure tailored for these exact parameters resolves these structural challenges. By utilizing deep engineering benchmarks, dedicated investment networks accelerate the transition from initial deployment to predictable enterprise scale. This targeted alignment enables scaling software groups to clear technical review hurdles smoothly, helping them capture market share in competitive enterprise sectors.
Comparative Performance Metrics: Sector Stability and Scaling Success
Market evidence confirms that startups backed by specialized capital pools achieve substantially higher five-year survival and scaling rates than those relying on generalist finance networks. When investment groups apply deep domain expertise to high-barrier technological verticals, portfolio companies navigate complex regulatory frameworks and commercial onboarding tracks far more efficiently.
The chart below outlines the five-year operational stability index across primary specialized technical segments compared to generalist market alternatives:
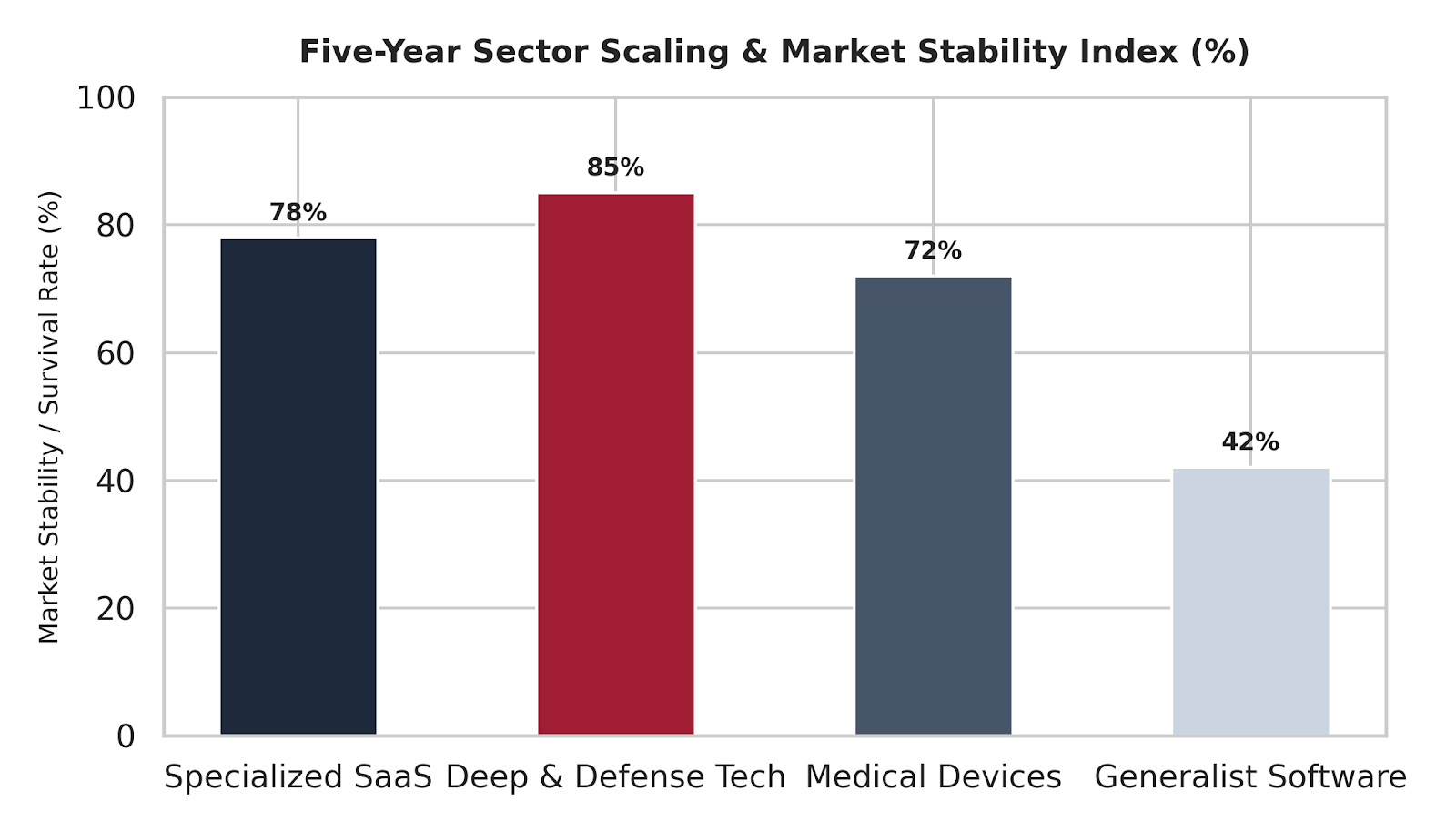
A clear vertical column chart mapping the five-year sector scaling and market stability index across different technical fields. Deep & Defense Tech shows the highest survival rate at 85%, followed closely by Specialized SaaS at 78% and Medical Devices at 72%. Conversely, Generalist Software shows significantly lower long-term stability with only a 42% survival rate, highlighting the critical performance advantages of targeted vertical incubation.
Five-Year Sector Scaling & Market Stability Index Breakdown:
Deep & Defense Tech: 85%
Specialized SaaS: 78%
Medical Devices: 72%
Generalist Software: 42%
Specialized Navigation in Medical Device and Deep Tech Sectors
The operational demands of healthcare and engineering technology require highly specialized, domain-specific investment approaches. Developing complex hardware-software configurations requires navigating strict validation tracks, including exhaustive clinical trials and stringent data-security reviews. For instance, a startup pioneering advanced medical diagnostic tools faces long, complex development cycles that standard software investors are rarely equipped to evaluate.
To manage these intense validation demands, sophisticated investment strategies utilize dedicated medical device venture capital support pipelines. These groups combine regulatory advisory teams with deep engineering networks to guide products smoothly from prototype to clinical validation. This specialized model ensures absolute alignment between technical code structures and complex regulatory mandates, transforming early-stage technology into a stable driver of long-term commercial growth.
Conclusion
Securing sustainable global market share in highly technical software and hardware spaces requires a deliberate, domain-specific approach to venture financing. Relying on generalist capital loops introduces significant regulatory alignment risks and unpredictable development timelines. Utilizing a targeted, vertically grouped investment framework ensures that scaling companies possess the capital stability, technical insight, and enterprise access needed to dominate complex markets. As global data security regulations and corporate validation standards continue to tighten, aligning with specialized, expert-backed cybersecurity venture capital structures remains an essential prerequisite for scalable technological expansion.
The explosive growth of commercial generative AI has created a significant and urgent data protection challenge for modern information security officers. While employees look for ways to streamline workflows, they regularly paste sensitive proprietary files, internal product code, and regulated customer records directly into unapproved public Large Language Models (LLMs). Because these public consumer tools often use user inputs to retrain their core algorithms, proprietary corporate data can easily leak out, exposing companies to massive compliance risks, intellectual property theft, and regulatory non-compliance. When these activities happen without IT approval, it creates a major blind spot known as shadow AI.
To counter this hidden risk vector, security-conscious organizations are deploying specialized shadow AI detection utilities. Traditional web filters and old cloud access tools fail to spot these threats because they cannot evaluate the text context inside natural language data movements. Modern shadow AI monitoring platforms solve this by combining real-time web traffic audits with advanced semantic analysis, allowing companies to detect unauthorized AI tools instantly. This review looks at how shadow AI risks develop, why passive web blocking fails, and what operational features distinguish dedicated discovery engines from basic legacy filters.
The Realities of the AI Discovery Gap
To build an effective data protection strategy, enterprise teams must recognize that shadow AI introduces far greater risks than traditional unmanaged software usage (Shadow IT). Historically, Shadow IT involved employees downloading unauthorized chat apps or cloud storage tools. While this introduced security risks, the underlying corporate data remained static inside an isolated storage environment.
Shadow AI completely changes this risk equation. When an employee inputs data into an unapproved web model, that information is absorbed into an active machine learning system. This creates an environment where an AI visibility tool enterprise solution is required to run a full AI asset inventory security scan, identifying precisely which unsanctioned models are consuming corporate data before it is trained out to public systems.
Data Interception Latency Under Evaluation
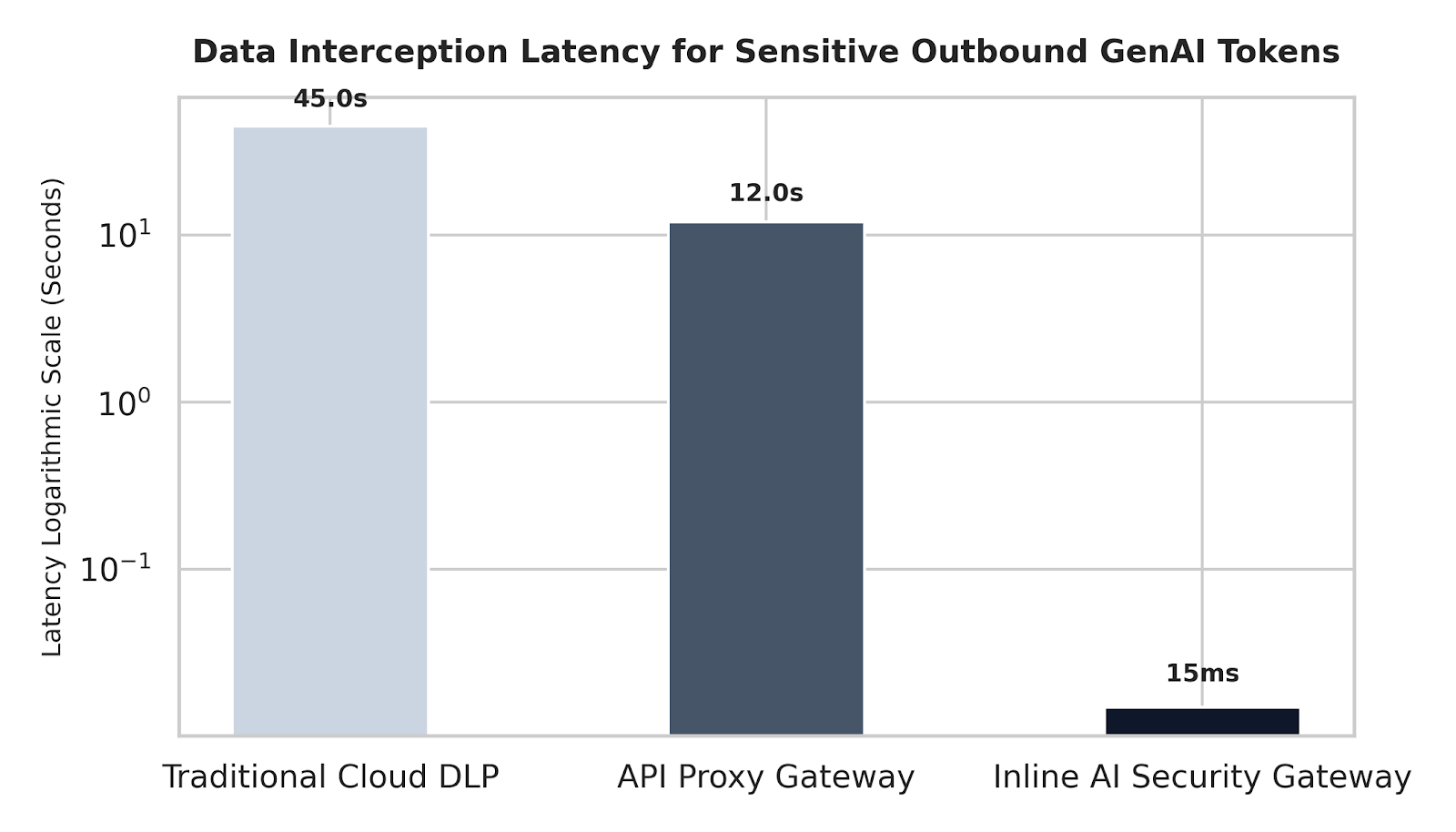
Manufacturing network deployment audits show that different filtering setups experience drastically different response times when evaluating and intercepting active token streams.
The visual matrix below maps intercept speeds across primary network deployment modes under intense outbound traffic loads:
Vertical bar chart showing data interception latency across standard industry controls, demonstrating traditional cloud DLP at 45.0s, API proxy gateways at 12.0s, and an inline AI security gateway at 15ms.
Core Elements of a Shadow AI Prevention Strategy
A robust security framework built to counter shadow AI must integrate several closely linked capabilities:
-
Continuous Employee AI Usage Monitoring: Running non-intrusive network audits to track where data is going across all active internal endpoints.
-
Automated AI App Discovery Enterprise Systems: Creating a real-time, living inventory of every external LLM, browser extension, and model API utilized across the firm.
-
Granular Policy Enforcement Rules: Giving security teams the ability to block dangerous web platforms completely while allowing safe, view-only access to helpful tools.
-
Contextual Data Protection Guards: Examining the meaning of outgoing data requests to catch sensitive corporate secrets that standard text-matching rules miss.
Selecting an Intelligent Governance Architecture
When evaluating new visibility tools, risk teams must prioritize platforms that allow them to adopt technology safely rather than trying to block all AI traffic. Complete bans are rarely effective because they encourage workers to find clever ways around security controls to maintain their productivity.
Transitioning to adaptive platforms that combine shadow AI monitoring with automated shadow AI prevention controls allows companies to manage shadow AI risks effectively. This dual capability protects data while helping teams extract maximum value from corporate technology assets.
Conclusion
The spread of unmanaged shadow AI tools represents a significant data security threat that requires active, automated monitoring solutions. The ease of access to public LLMs means that old web-blocking rules are no longer sufficient to protect corporate data. As these tools continue to evolve, adopting specialized, behavior-focused discovery engines is absolutely necessary for eliminating data blind spots — allowing organizations to safely embrace AI productivity while keeping corporate assets fully protected.
Live sports broadcasting has long required a substantial on-site presence — a full outside broadcast (OB) truck staffed with production personnel, commentary teams, technical directors, and supporting crew, all transported to the venue and back for every event. The cost and logistical complexity of this model have driven the broadcast industry toward a different approach over the past decade: remote production, also known as REMI (Remote Integration Model) or at-home production. By 2026, remote production has moved from an experimental workflow to the standard approach for many tier-two and tier-three sports events, and is increasingly used for major tier-one properties as well.
This article explains how remote production works, why the IP contribution encoder sits at its core, and what production teams should understand when evaluating solutions for REMI workflows.
What Is Remote Production?
In a traditional outside broadcast, the production team and production infrastructure are physically present at the venue. Cameras are operated on-site, the production switcher and replay system are in the OB truck, commentary is delivered from the venue, and the finished program is uplinked to the broadcaster from the truck.
Remote production inverts this model. In a REMI workflow:
-
Cameras are operated on-site by a minimal crew.
-
Raw camera signals are transmitted via IP from the venue to a remote production hub — typically a broadcaster’s headquarters or a third-party production facility.
-
Production switching, replay, graphics, and audio mixing all occur at the remote hub.
-
Commentary may be delivered from the hub using low-latency return video feeds to monitor on-site action.
-
The finished program is distributed directly from the centralized hub.
The result is a significantly smaller on-site footprint — sometimes as few as three or four crew members rather than 30 or more — with corresponding reductions in travel, accommodation, equipment transport, and local infrastructure costs.
The Role of the IP Contribution Encoder
The contribution encoder is the device that bridges the on-site cameras and the remote production hub. It receives camera signals at the venue, compresses them to a transmissible bitrate, and sends them over IP — whether that IP path is fiber, Ethernet, bonded cellular, or a combination — to the hub. LiveU’s remote production solutions are designed specifically for this workflow, enabling multi-camera feeds to be sent from sports venues over bonded cellular or fixed IP connections with the low latency and high reliability that live production requires.
The contribution encoder’s performance characteristics — latency, video quality, network resilience, and management capability — directly determine the quality and reliability of the remote production workflow. A production team that cannot trust the stability of their contribution link cannot trust their remote production workflow.
REMI vs. Traditional Outside Broadcast: A Cost and Logistics Comparison
| Operational Factor | Traditional Outside Broadcast (OB) | Remote Production (REMI) |
| On-site crew size | Large team (20–40+ personnel required on-site) | Minimal team (3–8 personnel required at the venue) |
| Transport cost | High logistical spend (heavy OB truck + massive crew travel) | Low logistical spend (minimal crew travel and gear transport) |
| Production equipment | Dispatched and maintained entirely on-site | Centralized, secure, and permanent at the main hub |
| Scalability | Linear limitations (one dedicated truck needed per event) | Highly scalable (one hub can simultaneously serve multiple events) |
| Network dependency | Low reliance on local external network uplinks | High reliance (stable, high-bandwidth contribution link is critical) |
| Carbon footprint | Elevated due to vehicle emissions and power generators | Substantially lower environmental impact across production loops |
Technical Requirements for Reliable REMI
The shift in operational efficiency that remote production enables comes with a corresponding shift in technical dependency. In a traditional OB, the production infrastructure is physically co-located with the cameras — if a cable goes bad, a technician is on-site to fix it. In a REMI workflow, the contribution link becomes the single most critical dependency.
Requirements for reliable REMI transmission include:
-
Low latency: Glass-to-glass latency below 200 milliseconds is typically required for director communication and replay decisions; sub-100ms is preferred for live commentary workflows.
-
High reliability: The contribution link must maintain stability across an entire broadcast window, including during the peak network congestion that often coincides with major live match moments.
-
Sufficient bandwidth: Multiple simultaneous 4K or HD camera feeds require 30–100 Mbps per camera of reliable uplink capacity.
-
Redundant paths: Production-grade REMI workflows use bonded cellular arrays as primary or backup connections, with fiber or satellite providing additional layered redundancy.
-
Remote monitoring: Production teams at the hub need real-time visibility into contribution link quality, with active alerting on any signal degradation.
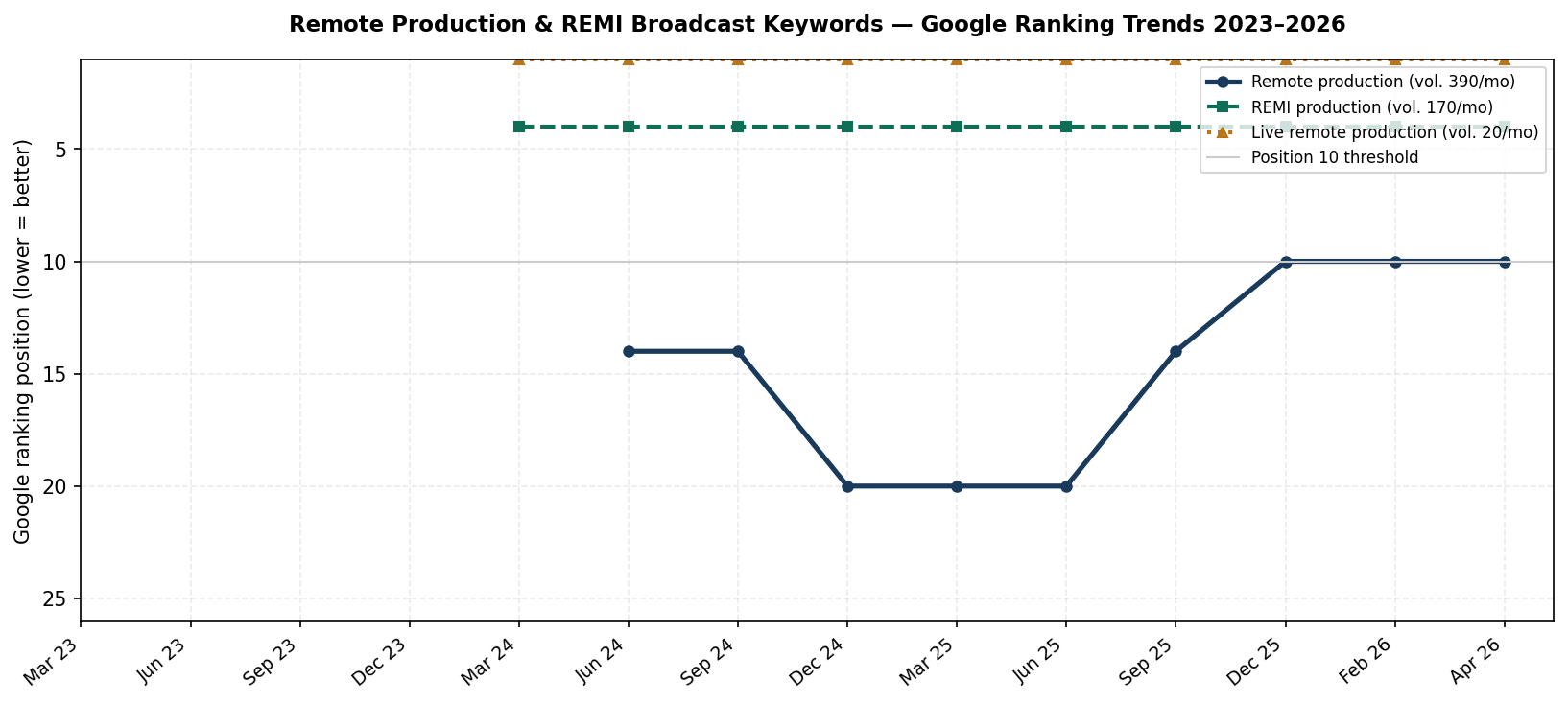
Line graph illustrating Google ranking position trends from 2023 to 2026 for remote production and REMI broadcast keywords, tracking specific monthly search volumes and top-10 visibility thresholds over time.
5G and the Next Phase of Remote Production
The arrival of 5G networks is accelerating remote production adoption. LiveU’s sports broadcasting solutions demonstrate how bonded 5G enables the bandwidth and latency characteristics required for multi-camera REMI from sports venues that previously required dedicated fiber infrastructure for contribution. A bonded 5G unit can deliver multiple simultaneous 4K camera feeds from a venue without any local fiber — a practical option that dramatically reduces the infrastructure cost of remote production from smaller venues.
For broadcasters covering a large portfolio of sports events — including lower-tier leagues, regional competitions, and international fixtures — the combination of 5G connectivity and remote production infrastructure makes economically viable coverage of events that would otherwise be impractical to broadcast.
REMI in Practice: What Has Been Deployed
Remote production has been used for major international sports events including UEFA Champions League matches, Olympic Games coverage by multiple broadcasters, domestic football leagues across Europe and North America, and motorsport coverage across multiple series. According to the Sports Video Group (SVG), remote production now accounts for a significant and growing proportion of sports broadcast output globally, with adoption accelerating since 2020.
The workflow is no longer experimental — it is a production-proven approach with a growing body of documented deployments across sports broadcasters, rights holders, and production companies.
Conclusion
Remote production and REMI workflows represent a structural shift in how live sports broadcasting is produced. The operational and economic case — smaller on-site footprint, centralized production hub, scalability across multiple simultaneous events — is sufficiently well-established that it is now the default planning assumption for many broadcasters covering sports at regional and national levels.
The IP contribution encoder sits at the heart of this workflow, and its reliability under real-world venue conditions determines the viability of the remote production model. Solutions that combine bonded cellular resilience, low-latency transmission, and robust management platforms address the core technical requirement. LiveU’s remote production portfolio, with deployments documented across major sports events globally, represents one of the established options in this space.
Targeted Vertical Incubation: Strategic Alignment in Technical Software Venture Co-Investments
The Critical Technical SEO Audit Checklist for Enterprise SaaS Environments
Shadow AI Detection: Regaining Visibility Over Unsanctioned Enterprise Tooling

-

 Business Solutions2 years ago
Business Solutions2 years agoLive Video Broadcasting with Bonded Transmission Technology
-

 Business Solutions1 year ago
Business Solutions1 year agoThe Future of Healthcare SMS and RCS Messaging
-

 Business Solutions2 years ago
Business Solutions2 years ago2-Way Texting Solutions from Company Message Services
-

 Business Solutions2 years ago
Business Solutions2 years agoCommunication with Analog to Fiber Converters & RF Link Budgets
-

 DSRC Communication1 year ago
DSRC Communication1 year agoThe Crossroads of Connectivity: DSRC vs. C-V2X Technologies in Automotive Communication
-
Electronics3 years ago
AI Modules and Smart Home Chips: Future of Home Automation
-

 Business Solutions2 years ago
Business Solutions2 years agoWholesale SMS Platforms with OTP Services
-

 Business Solutions1 year ago
Business Solutions1 year agoChoosing the Right B2B Digital Marketing Agency: A Guide