Cybersecurity
Securing Agentic AI: Mitigating Runtime Risks in Enterprise AI Agents

The rapid integration of autonomous AI agents across corporate networks has introduced an entirely new class of application security vectors. Unlike static Large Language Models (LLMs) that merely answer text queries, agentic AI systems are built with high levels of autonomy—possessing deep read/write access to enterprise APIs, corporate databases, and system tools. These tools allow agents to execute independent actions such as scheduling calendar invitations, pulling customer records, or refactoring codebase files without constant human supervision. However, giving autonomous tools direct access to business infrastructure exposes them to significant software flaws. The volume of data handled by these systems makes human monitoring mathematically impossible, and the consequences of a compromised agent loop can lead to massive corporate data leaks, system hijacking, or widespread data corruption.
To defend against these new threats, enterprise security teams are moving away from legacy web gateways toward dedicated, context-aware runtime protection. Because autonomous agents operate dynamically, standard signature-based security rules cannot predict or stop malicious agent behaviors. Securing these environments requires complete visibility into agent activities at runtime, combined with real-time guardrails that evaluate the safety of every command before it is executed. This review examines how agentic AI risks occur, why real-time monitoring is critical for organizational stability, and what defense mechanics separate robust runtime protection platforms from legacy cloud security architectures.
Understanding the Vulnerability Landscape of AI Agents
Securing autonomous workflows requires a clear understanding of how adversarial inputs trick machine learning models. Traditional application security relies on a strict separation between code commands and user data. In agentic workflows, however, natural language text acts as both the code and the data simultaneously. This structural design allows bad actors to manipulate agent behavior by embedding malicious text strings within standard web forms or public documents.
When an agent processes this manipulated data, it mistakes the hidden instructions for developer commands. This can trigger an unauthorized action, such as forwarding internal database records to an external email address. Known as prompt injection, this technique can bypass standard text filters easily. This threat highlights why deploying an inline ai observability layer is essential for keeping close tabs on model context shifts.
Core Runtime Vulnerabilities in Autonomous Ecosystems
Professional security teams evaluating agent deployments must protect against several key threat vectors:
-
Indirect Prompt Injection: Occurs when an agent reads a poisoned third-party source (like an email or web snippet) containing hidden instructions that alter its behavior.
-
Malicious Data Poisoning: The intentional altering of underlying vector databases or retrieval-augmented generation (RAG) sources to corrupt model outputs over time.
-
Unauthorized Tool Execution: Exploiting an agent’s open API privileges to trigger backend system tasks that the current user does not have permission to execute.
-
Model Context Exfiltration: Tricking an agent into revealing its internal system prompts, system instructions, or sensitive data tokens during conversation.
Operational Evaluation: The Shadow AI Proliferation
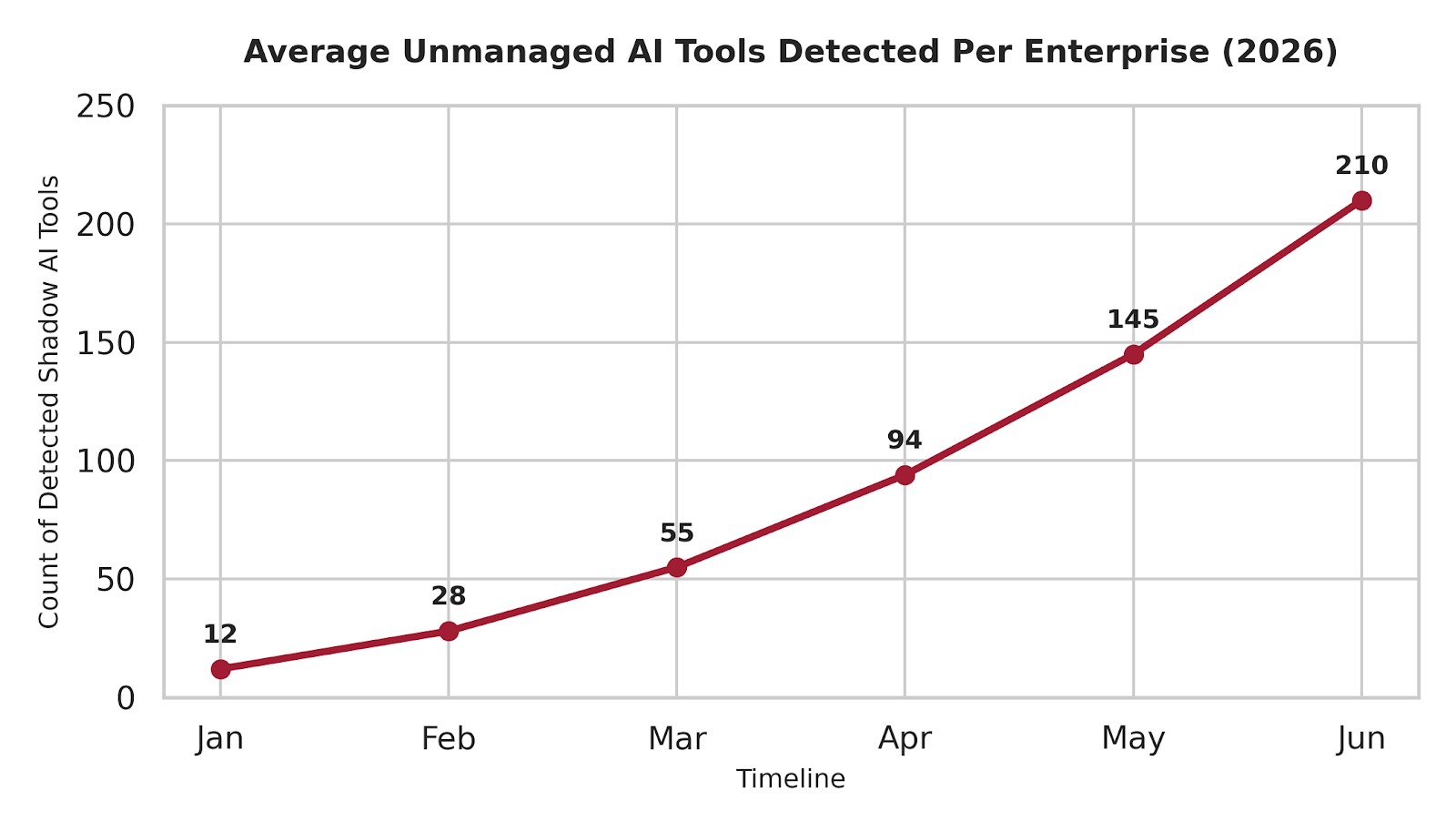
A major factor complicating this threat landscape is the sheer speed at which unapproved autonomous plugins and model connections slip into production environments. Before security teams can even evaluate runtime behaviors, they must first find where these endpoints exist.
The trend data below highlights the average monthly volume of unmanaged shadow AI endpoints discovered across commercial networks, emphasizing the urgent need for structural visibility:
Line graph tracking the monthly trajectory of average unmanaged shadow AI tools detected per enterprise from January to June 2026.

Implementing Robust Agentic AI Governance
Protecting enterprise networks against agent failures requires a defense framework built specifically around runtime behaviors. Security managers cannot rely solely on pre-deployment software scans because an agent’s risk level changes dynamically based on the data it consumes.
Organizations are executing a broad, industry-wide move toward establishing verifiable application security for ai agents across core lines of business. Deploying continuous telemetry discovery, enforcing strict API boundaries, and embedding real-time behavioral guardrails allows organizations to safely use advanced secure ai agents to drive business efficiency without introducing massive compliance or compliance exposures.
Conclusion
Securing agentic AI architectures has quickly become a top priority for competitive enterprise security operations. The combination of high system privileges and natural language processing makes autonomous agents a highly vulnerable surface area that legacy security wrappers cannot adequately protect. As companies continue to roll out advanced agent workflows, implementing real-time, behavior-focused AI runtime security frameworks remains an absolute necessity—ensuring organizations can safely adopt AI technology while protecting corporate assets from sophisticated exploit loops.
Review Disclaimer
This article is an independent technical review for informational purposes only. It does not constitute formal software architecture engineering, infrastructure procurement consulting, or corporate compliance audit advice. Readers should test runtime behavioral controls, map local data dependency chains, and verify specific sandbox isolation capabilities against their internal security policies before executing commercial platform choices.